您现在的位置是:首页 > IBM 发布了自动为新闻播报生成字幕的 AI 模型
IBM 发布了自动为新闻播报生成字幕的 AI 模型
简介近日,IBM 研究院发布了自动为新闻播报生成字幕 AI 模型的研究报告。据两项测试实验的结果显示,该语音识别系统的错误率分别为 6.5% 和 5.9%,而人类识别的错误率分别为 3.6% 和 2.8%。
近日,IBM 研究院发布了自动为新闻播报生成字幕 AI 模型的研究报告。据两项测试实验的结果显示,该语音识别系统的错误率分别为 6.5% 和 5.9%,而人类识别的错误率分别为 3.6% 和 2.8%。

△ 图源:IBM,下同
早在两年前,IBM 就已经创造了对话式电话语音领域(CTS)转录的性能记录。在这个领域,语音识别系统需要做的工作很多。例如,系统必须处理失真、以及来自多个不同电话通道的即兴演讲,并且这些对话式语音还可能有多个对话者重叠、中断、重新开始或重复确认的情况。
新闻播报(BN)的语音识别任务也很有挑战性。语音识别系统需要处理多种说话风格、背景噪音以及广泛的新闻领域内容。一些情况下系统还得处理多种题材混合的语音材料 —— 像是现场采访、电视节目的剪辑内容等。
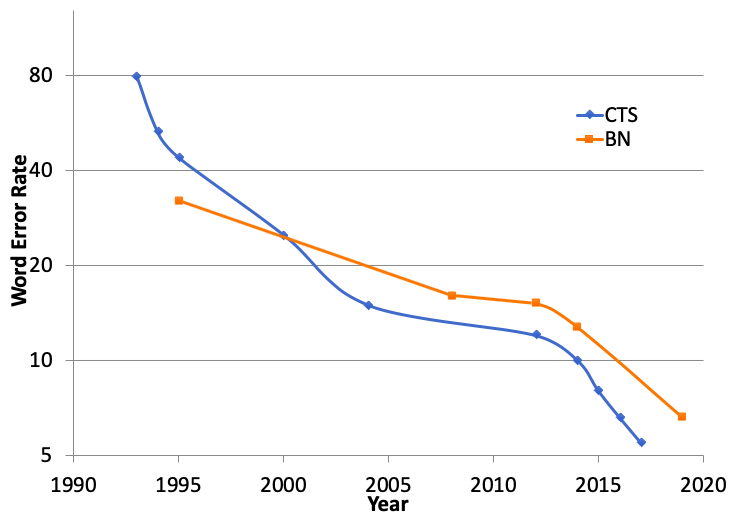
△ 研究进展:CTS 及 BN 测试集单词错误率逐年降低
为了成功地识别复杂的语音内容、给新闻播报内容生成字幕,IBM 研究团队通过语音识别技术,建立了一套深度神经网络。该深度神经网络在整合了长短期记忆网络和深度残差网络(residual network,ResNet)的基础上,结合了辅助的语言模型。其中,以 ResNet 为基础打造的声学模型是含有多达 25 个卷积层的深度卷积网路,使用 1,300 个小时、多种不同的新闻内容资料来训练生成字幕的 AI 模型。
虽然机器的语音识别正在逐渐接近人类水准,但目前的实验数据显示,人类的语音识别表现仍旧好得多。IBM 也表示,在这一领域仍有很大技术改进的空间。
文章转载自 OSCHINA 社区 [http://www.oschina.net]
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3cn0udci9ym88
相关文章
文章评论
栏目导航
点击排行
-
现代化开发环境最佳实践
自从做开发一来,一路经历了各种软件的此起彼伏,可谓百家争艳,今天说一说发现的一款特别好用的跨平台集成开发环境软件FlyEnv。
-
清空macOS动态壁纸占用几十GB空间
macOS新版本带来了各种类型的视频动态壁纸,这些壁纸一旦下载,系统不提供删除功能,占用磁盘空间有时候高达几十GB。
-
Navicat数据库软件免费了!推出Navicat Premium Lite:支持MySQL、Redis等
数据库管理工具领域的知名品牌Navicat,推出其免费版本——Navicat Premium Lite,用户可从Navicat官网下载体验这款软件。
-
一行代码永久关闭Win11自动更新
Win11自动更新可以帮助系统保持最新状态,但有时也会给用户带来不便。本文将介绍如何使用一行代码永久关闭Win11的自动更新,让用户能够更灵活地控制系统更新的时间和方式。
-
WIN版虚拟显示器usbmmidd_v2
在没有物理显示器的情况下,通过远程软件向日葵或者todesk连接主机,默认显示640*640分辨率,而且无法修改,网上存在一些付费版虚拟显示器软件,今天再次推荐一种简单免费的方法。
-
解决连接MySQL时报"The server requested authentication method unknown to the client”错误
mysql8.0与mysql5.0存在一些差异,经常在项目中遇到,这次是关于用户认证的。
-
微软对自己最终成功过渡到Arm架构充满信心 MacBook Air是最大假想敌
由于Arm的性能与能耗优势,消费终端终将被Arm统一;其实Arm版本Windows11早就准备好了,微软元件是有的,就是没把握好先发优势,其实2012 年,微软就首次尝试通过 Surface RT将 Windows 过渡到 Arm 芯片,奈何一直没有好的CPU支持,之前也出过几款高通的ARM笔记本,可是性能太拉垮了,这次XElite希望微软和高通能抓住机会,不让Apple在arm版本pc一家独大。
-
8688元起硬刚iPad Pro!微软新Surface Pro发布:性能提升90%
Windows Arm Pc终于能与Apple M性能比肩了。华为、微软都已经采用OLED了,这个还能5G,遥遥领先啊,Apple动作真慢。
-
Apple 发布设计轻薄、动力磅礴的全新 iPad Pro
 加利福尼亚州,库比提诺 Apple 今日发布设计轻薄、动力磅礴的全新 iPad Pro,将便携性和性能表现双双提升至新境界。全新 iPad Pro 提供银色和深空黑色两种可选外观,以及宽大的 13 英寸机型和极致便携的 11 英寸机型两种可选尺寸。
加利福尼亚州,库比提诺 Apple 今日发布设计轻薄、动力磅礴的全新 iPad Pro,将便携性和性能表现双双提升至新境界。全新 iPad Pro 提供银色和深空黑色两种可选外观,以及宽大的 13 英寸机型和极致便携的 11 英寸机型两种可选尺寸。 -
你见过的最糟糕的代码是什么?
编程第一守则,代码能跑你就别动!
